- Published on
On Large Language Models and Roadside Bot Geologists
Geology Field Trip Stop Introduction Statements
Although you do not have to spend a lot of time in the field to be a geologist, the experience of standing beside a cliff face while someone expertly points out the details of the rock formations, contextualizing them within the broader regional geology, and using those details as examples to illustrate fundamental geological concepts is a quintessential part of geology education that forms a common shared experience. In fact, there exists an entire genre of books called "roadside geology of [___]" that capitalize on the idea of using point locations along a route to build a larger understanding of geological phenomena. The information in these books is presented in a manner that mirrors the traditional field trip experience.
 Figure 1. Photo of a group of Franklin and Marshall College students standing in front of SP crater on a geology field trip across Arizona.
Figure 1. Photo of a group of Franklin and Marshall College students standing in front of SP crater on a geology field trip across Arizona.
Usually, someone with deep knowledge of the area is needed to lead these excursions, as they are familiar with the stops along the way and have spent many hours researching and organizing the information to be delivered at each stop. This includes accounting for the audience's level of knowledge and the time available to deliver the content. However, there are times when such a knowledgeable guide is not available. Perhaps a geologist, or simply someone with an interest in geology, is driving along a road or looking at a map and wishes they had access to information about the local geology and its broader context.
Is it possible to create a bot that can take on at least some of the role of a field trip leader, by finding and presenting relevant geological information for an arbitrary point location?
With the recent jump in natural language processing abilities associated with large language models (LLMs), it is increasingly plausible we might be able to automate information delivery in a way that mirrors, at least a little bit, the experience of a field trip. This document poses the question of whether we can create a bot that for any given point location expressed as a latitude and longitude, provides an introductory statement like that might be delivered at the beginning of a field trip stop. Such a task was previously impossible to do programmatically. This blog post explores the ways in which large language models make it easier to accomplish this task while also highlighting the challenges that remain.
The context of when was this written
This was written in March of 2023. There has been a surge of interest and activity in large language models driven by the capabilities of OpenAI's ChatGPT application and foundational models. The tech community on Twitter talks about nothing else. My local paper in Houston, Texas is exploring using ChatGPT to help write taco reviews.
While I've previously done some work and side projects in more traditional natural language processing areas, this is my first experiment using pre-built large language models in a side project. I have no idea what I'm doing. There's a high chance I'll look back on this writing in 3-12 months and groan, but for now it is helping me collect my thoughts.
 RIP Bailey the "I have no idea what I'm doing" dog
RIP Bailey the "I have no idea what I'm doing" dog
The user experiences I aim to build
To user experience I am trying to build is:
- The user inputs a latitude and longitude.
- This could be via text input form, it could be through you giving your phone's browser permission to access your location, or it could be through inputting a city, state, and country name that is then geocoded to a point.
- In all cases, it is a point location.
- The user is told a narrative about the geology at that point.
- Initially, the idea is the information involved is:
- Geology at the surface at that point.
- Regional context of that local geology.
This mirrors in many ways the "real-world" geology field trip experience. Someone tells you about the rocks in front of
you and then puts them into context. As this is a quick experiment as a side project not related to work,
I am just writing it as a bunch of hacky python code that gets run from a terminal by calling python main.py.
All the code is available in the LAGDAL repository & open source licensed.
Two APIs are used that require keys, OpenAI and Bing Maps.
Prior art with Macrostrat API and text-to-speech in a simple web page
I've previously experimented with this sort of idea in an Observable notebook called "Stratigraphy Speech" that was created shortly before a multi-state road trip. I wanted to have something an automated "road-side geology of ___" book that I could turn on from my phone while driving.
This approach uses no large language model or any other type of natural language processing. It calls a singular API with a point location and parses the data it gets in response.
An observable notebook is a website that holds the JavaScript code and executes it at the same time. The webpage asks for the user's location via the location API built into every browser & permission to play sound. Once it has those, it uses the location to call the Macrostrat API, which returns data in a JSON that is about the top two geologic units at that location. This JSON file is parsed by several different JavaScript functions that you can see in the notebook and the resulting information is combined with pre-written text into a standard one-size fits all narrative. That narrative is then spoken to the user via browser's text-to-speech capabilities, which all browsers now have but are rarely used.
The end effect is a webpage you can give permissions for in advance and then open later. Upon pushing one button, it will tell you about the geologic unit at the surface at that location.
Limitations of Macrostrat & string manipulation approach
Upon using this, there are a few limitations that quickly become obvious. First, due to the narrative being one-size fits all and deterministically created from well structured data, it can get kind of boring to hear again and again as you drive down the road. Even if the unit's age and lithology vary, all of the glue words stay the same every single time you try to get information. Second, there is no regional information or contextual information. All you get is what the API gives you, which is lithology, age, and maybe interpreted depositional environment, all data originally extracted from a geologic map.
The problem of trying to scale creating geological narratives from data APIs: Variation
Ideally, you'd be able to not just get an individual point location data read back to you in a single construction. You would also get regional geology, historical narrative, information on what is unique, etc. The content you want as narrative could reasonably vary, just like actual field trips. You might want what is said at the second stop to refer back to what is said at the first stop. You might want to know what is unique about this location relative to others. There are a variety of other variations in what information is provided, how it is provided, and how the user interacts with it that quickly start to pile up if you want to make something useful and pleasant to use.
Types of variations in the information that might be desired:
- Short summary vs long with details
- Point-based information vs. regional-based information
- General information vs. sub-field specific
- For general audience vs. for expert audience
- How this point location differs from the last location and what that tells us
Types of different interactions with information that might be desired
- one-way or chat
- statement vs. question & answer
- text or speech
To do all this with deterministic traditional programming becomes both complex and tedious rather quickly. Well structured standardized sources of information must be located, assuming they exist. Oftentimes, they don't exist. Where they do exist, many different functions must be written for each new piece of well-structured information and each new way to present that information.
Using traditional deterministic coding to programmatically create narratives from data APIs becomes too laborious quickly unless all the information needed is already very well structured in a finite number of known places and the number of ways people want to interact and hear about that information is limited.
In contrast, doing this with a large language model is easier.
What Large Language Models Offer
Large language models (LLM) offer an improvement on this development experience with a lower labor to functionality slope. Their outstanding ability to predict reasonable sounding next words given a prompt enables them to do a variety of tasks directed by plain language instructions, also known as "prompts", instead of abstract code.
Because they are good at predicting the next words given a sequence, they can do the following tasks:
Skilled summarization
LLM can summarize three pages of text into a single paragraph. They can also summarize text with a focus on specific types of content or in a specific style of writing or speaking. Instead of writing many functions to process many different types and sizes of text in specific ways, you write a few prompts describing what you want the output to be in general.
Flexible extraction
LLM can extract keywords, concepts, and specific information from text. When my previous team at NASA created a model to predict topic tags against abstracts and READMEs, it required a pre-existing dataset of millions of labeled abstracts and months of training and evaluating different models. Now you can get comparable performance from an OpenAI model without having to do any of the data preparation or training yourself. It shrunk a 6-12 month project to a day. Additionally, you can just provide a list of possible tags in the prompt, or none at all, and it returns useful predictions. It is a serious jump in capabilities compared to what existed one or two years ago.
General knowledge....to some extent
Although LLMs are infamous for making up things that sound right, they can also return general knowledge accurately at times. Figuring out when to trust such information evolves trial and error before you start to be confident of the accuracy of the text a given prompt produces. Functions to validate the information or concept certain aspects about it are also possible.
How does ChatGPT do with single geology questions:
Let's establish how well another single prompt works. We can use the ChatGPT API to test this.
If asked to "Describe the geology of [insert point coordinate]", it defers as the task is not something it is comfortable doing.
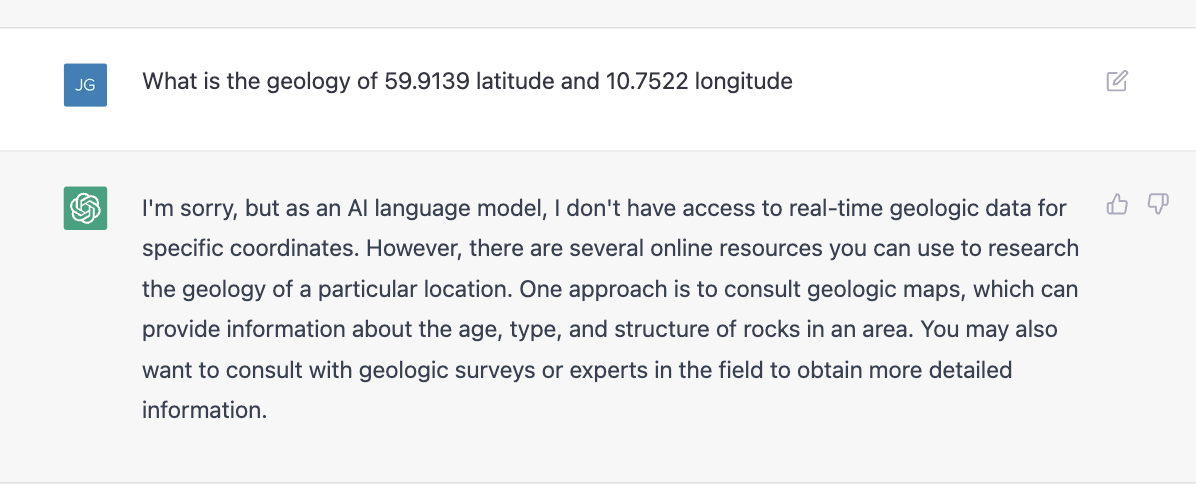
If I instead ask it to describe the geology of a well known location, it complies but does so in a way that is not entirely correct. Although there is precambrian bedrock in the area, a geologic map of the area (which you can find in this research paper or on Macrostrat ) shows there is more recent glacial deposits on top in addition to much older metamorphosed sediments.
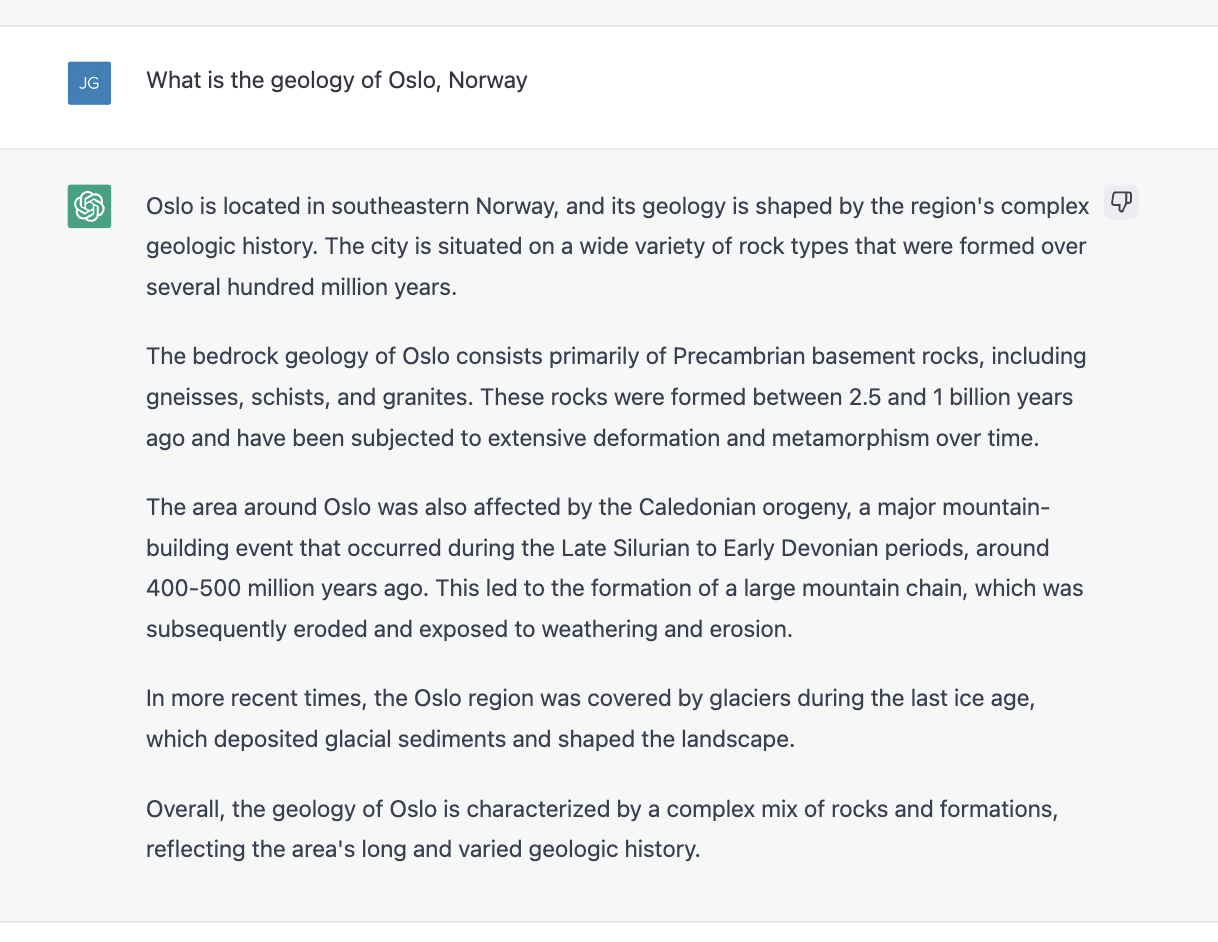
Interestingly, if you use the thumbs down button to let ChatGPT know it is incorrect, it asks how it is incorrect. It then uses that information to suggest an improvement as shown below on the right side.

As another example, if you just ask ChatGPT to "Describe the geology of Houston, Texas", it gets some information wrong. The formation names and the ages ChatGPT returns are common formations but not actually the top two formations at that location. They are very common formations to be discussed in the context of Houston-based oil and gas companies working in the Gulf of Mexico. I suspect there is much more literature in OpenAI's training dataset on these formations written by people from Houston than on the formations that are actually present in the Houston area.
As superb prediction machines, LLMs can give inaccurate information when the most common text that shares the words in the prompt isn't exactly what the prompt is asking. Other times, it seems there likely isn't anything in its training that relates to the question in the prompt.
An approach with data first, LLM Second
To get around these limitations, we can combine LLMs with geologic data APIs and easily searchable text on the subjects requested in the prompt. We can also use cleaning and validation functions to figure out what information might be more trustworthy or relate the most to the given question.
The act of combining deterministic APIs, LLMs API calls with different prompts, and various validation and data cleaning functions is often called "chaining".
For more about "agents", "chains", and other concepts for building applications with LLMs, check out the documentation for Langchain or Semantic-Kernal, two libraries for calling OpenAI-type model APIs.
For our approach, we'll try to a simple chain that relies on APIs with factual information first, then use LLMs to reorganize that information into a form that is more useful. We'll also use LLMs when our factual API data sources strike out.
Where to get deterministic geology and geographic data
Before describing the chains, we will first talk about where to get the data from if not entirely from the large language model. Currently, I am working with two places to source geologic information and a geocoding service to get place names to go with the initial point location that we start everything out with.
Bing Geocoding API:
Given that the process I am developing starts with a point location but the information I want to provide includes regional context, I need the words to find the appropriate regional names. To get them I use the Bing Maps Geocoding API. Under a certain amount of calls, the geocoding service is free. I provide a latitude and longitude, it returns a street address, including state and country.
MacroStrat: Well-structured information about a point location
Macrostrat describes itself as "the world's largest homogenized geologic map database". You can find a longer description on their website. We use their API to source geologic data for a point location. One endpoint of their API provides stratigraphic column information across most of the United States of America and Canada. Another endpoint grabs the bedrock geology from large regional and global maps. Where the stratigraphic information exists, that is preferred due to higher resolution information. In addition, it lets you ignore the boring "recent alluvial soil" that sometimes covers the most interesting bedrock geology underneath.
Although Macrostrat is great as a single API that gets you point location information around the world, it is limited in that it doesn't provide any regional information or geologic history. It just says what types of rock exist at a given point. For that broader type of regional or historical information, we need to look elsewhere.
Wikipedia: Semi-structured sources of regional information
One place to get regional geologic information is wikipedia. There are a variety of python packages built to call the Wikipedia API. We can use them to search for "Regional geology of [insert location]", get back pages, evaluate the pages by some criteria to see if they are actually about the geology of where we care about, and then have a LLM summarize the regional geology into a paragraph instead of however long the Wikipedia page is.
This approach often works out great as there are many wikipedia pages written about the geology of states, provinces, and countries. For example, this is a wikipedia page about the Geology of Ohio. It is the first Wikipedia search result for 'Geology of Ohio'.
However, other times the page returned does not describe the geology of the location we're interested in. As we try to get state or province level information from the geocoding API, that geographic name is not always useful when used to search for geology pages on wikipedia. For example, a point location in the city of Oslo, Norway returns a province name of 'Oslo' as well. If we search for Geology of Oslo on wikipedia, we get several pages, but nothing that is exactly geology of Oslo Norway. Pages that return are "University of Oslo", "Geology", "Natural History Museum at the University of Oslo", "Oslo Graben", and "Geology of Great Britain".
What we use to get around this behavior is (1) a prompt that evaluates whether the wikipedia page includes the information we need (2) and a fallback strategy that uses a prompt to generate a list of geologic regions for the country and then another prompt that identifies which of those regions the location in question is within.
Other unstructured sources of geology information: bing search, literature, etc.
Other sources of information might be literature or search engine results. I am not currently doing this, but opportunities exist. For example, the Macrostrat map API often provides a way to grab references to literature associated with the map. There's also entire services devoted to semantic search of journal articles that might be useful.
When prompts give accurate results reliably
One source of factual information I used from prompts was the square area of each country.
promptDecideIfCountySmall = PromptTemplate(
input_variables=["country"],
template='What is the area of {country} . Return only an integer and no other text.'
)
After testing this with several countries, I convinced myself the answers were reliable. It was faster to do this then figure out how to possibly source this information from say wikipedia's data APIs or another API source. This information was used to make a decision whether to use the state name for regional context or the country name for regional context.
Chaining rule-based functions and prompt-based functions
As mentioned above, I have two types of functions that I use to get information. One type is a rule-based function and the other uses LLM prompts. Combining multiple of these together is a chain.
High-level description of the chain used in this experiment:
- Send latitude and longitude to Bing Maps geocoding API, get back a street address
- Send latitude and longitude to Macrostrat API, get back geologic information about surface layers in a JSON sourced from a geologic map.
- Use a prompt powered by OpenAI's GPT-3 to turn the JSON data on lithology, age, and depositional environment into a paragraph of text.
- Parse street address into city, state, country.
- Use a prompt powered by OpenAI's GPT-3 to get the square area of the country. Based on the result, decide to use the state or country name for the next step.
- Use the state country to search for a wikipedia page about the geology of that region.
- Use a prompt powered by OpenAI's GPT-3 to summarize the wikipedia page into a paragraph of text.
- Use a prompt powered by OpenAI's GPT-3 to determine if the summarized text is about both "geology" and the "region".
- If the text is not about both "geology" and the "region", use a prompt powered by OpenAI's GPT-3 to ask for the regional geology areas of the state or country, then use that as a fallback. I have found asking about the regional areas first is more likely to get a reasonable answer then directly asking for the regional geology.
- Use a prompt powered by OpenAI's GPT-3 to combine two local point summary and regional summary into a single several paragraph summary using the voice of a professor on a field trip.
Results
Results for "latitude": 41.512, "longitude": -82.9377 (Port Clinton, Ohio)
Good day, my students! Welcome to our geology field trip. We are in the Port Clinton area of Ohio, which is composed of two distinct geological layers.
The top layer is a glacial and lacustrine depositional environment, estimated to be 0.0117 million years old and composed of 48.81% gravel, 44.05% sand, and 7.14% clay.
The bottom layer is a marine and inferred marine depositional environment, estimated to be 358.9 million years old and composed of 37.5% shale, 12.5% sandstone, 31.25% limestone, and 18.75% dolomite.
These two layers are separated by approximately 40 million years.
The region we are in is part of the Glacial Region of Ohio, which is located in the northern part of the state and is characterized by glacial deposits from the Pleistocene Epoch.
The soils in this region are generally deep and fertile, making it ideal for agriculture.
We are also close to the Dissected Plateau Region of Ohio, which is located in the central and eastern parts of the state and is characterized by rolling hills and valleys that were formed by the erosive forces of rivers and streams.
Results for latitude = 9.34 longitude = -82.25 (Bocas del Toro, Panama)
Greeting the class on their geology 101 field trip, Professor John McPhee began by describing the geology of Avenida G Norte, Bocas del Toro, Bocas del Toro District, Bocas del Toro, Panama.
The area is composed of two stratigraphic layers.
The Upper Cretaceous unit, which is approximately 72-66 million years old, is composed of 50% sandstone and 50% shale, likely deposited in a shallow marine environment.
The Lower Cretaceous unit, which is approximately 145-100 million years old, is composed of 40% sandstone, 40% shale, and 20% limestone, likely deposited in a shallow marine environment.
The Valiente Formation, part of the Bocas del Toro Group, is located in the region and dates back to the Serravallian period, part of the Neogene period.
This formation is composed of sedimentary rocks and preserves fossils of bivalves, gastropods, and scaphopods, providing insight into the regional geologic history.
The Valiente Formation is important for understanding the geologic history of the region, as it provides evidence of the faunal composition of the Caribbean during the Neogene period, as well.
Results for latitude = 37.7749 longitude = -122.4194 (San Francisco, California)
Good morning, class! Today we are going to explore the geology of the Pacific Province, located in the United States.
This province is geologically young and tectonically active, with the Sierra Nevada range forming a barrier along the western edge.
The Cascade volcanoes form an arc-shaped band from British Columbia to Northern California,
and the Columbia Plateau province is covered by 500,000 km2 of basaltic lava.
These features were formed over millions of years of plate tectonics, weathering, and erosion.
At our specific location, 2340 Market St, San Francisco, California 94103, United States, the top two layers are separated by millions of years of deposition.
The top layer is 0 to 2.58 million years old and is composed of 14.29% gravel, 71.43% sand, and 14.29% clay.
This layer was likely deposited in a fluvial environment.
The bottom layer is 3.345 to 12.1775 million years old and is composed of 2.38% gravel, 2.38% sand, 12.78% siltstone, 12.78% sandstone, 8% conglomerate, 2.67% limestone, 9.38% volcanic, 13.
You can find more results in this JSON . More recent results at the end.
Learnings from current experiments
Find the results impressive for small amount of time spent developing
The results aren't perfect, but they're better than my prior attempts without LLMs. The results are more variable in their narrative construction and more interesting than the prior attempts without LLMs involved. The read like a person might have said or written them. I do not get bored with them like the prior attempts using basic parsing functions of Macrostrat API results. The results seem accurate to my knowledge of the geology of the local areas almost entirely. The inclusion of Macrostrat API results and wikipedia page summaries are a big improvement in accuracy over LLM alone.
In general, I'm impressed with the results for the amount of time I've spent on this project.
Lots of room for improvement
Math
One source is errors is that the text-davinci-003 model I'm using has some known issues with math. As a result, it sometimes
tries to describe the gap between layers in terms of missing time and gets the numbers wrong. There are math prompts to fix this, but
I haven't tried them yet.
Length limits
The degree to which the local and regional geologic information are merged together well also seems variable. I suspect I might be running out of tokens in the output and therefore which ever one is discussed second gets cut short. I have not yet investigated this yet. I suspect there might be an easy fix available.
Better decisions on what part of regional geology to talk about
At times the regional geology descriptions seem to have lost the narrative thread when summarizing too much. One possible way to improve this is to combine several layers of prompts to identify what parts of the regional geology are more interesting at this location then focus the summary on those parts. In some locations, there are multiple episodes of mountain building that dominate the regional geology. In other locations, rifting or sea level change is more of the main story line.
Better connection between local and regional geology
It would also be interesting to see if the focus of regional geology descriptions could be directed to better align with the surface bedrock geology of that locality. This would do a better job of putting that location into the regional context. Right now, it combines both into a single summary but does not really select parts of the regional geology to talk about based on the local geology.
Big boost in productivity
My previous experiment using the Macrostrat API in an Observable Notebook worked, but it was lacking in content and tended to become tedious after a while. Additionally, it left me wanting more context beyond information specific to that point. While writing code to create more variable narratives was possible, it would have taken considerable time. The OpenAI API's ability to rephrase and summarize content provides the opportunity to utilize additional information from unstructured data sources beyond structured data from an API. It also provides easy pathways to reword underlying information in different styles or focus on different parts of the information. Although this was technically possible with more traditional methods, the amount of time required to build each new feature was substantial. In contrast, combining data APIs, search results, etc. with LLM prompts to achieve the same results feels much easier.
The slope of labor for functionality is much lower if LLMs are used.
Comparable boost in productivity to the appearance of NASA Worldwind / Google Earth
The thing it feels most similar to out my own experiences is the appearance of NASA Worldwind / Google Earth. When I started graduate school in 2004, I needed aerial imagery of the area I was going to do field work at later that year. The process to get aerial imagery at the time involved looking at squares on a map, sending an email with credit card information to purchase images of that square on several different days, and then waiting two weeks for the images to arrive on a physical CD mailed via the postal service. You would hope the days you purchased did not have clouds otherwise you would have to do the whole cycle again. After I did that once, NASA Worldwind, and shortly after Google Earth, came out. Instead of waiting two weeks, you could sit at your computer and scroll everywhere on the planet and instantly see satellite images of the entire globe. It blew everyone's mind. The entire research group was behind a computer calling out new locations to scroll to for the rest of the day and part of the next. It wasn't a tiny step change in productivity, it was a being thrown across the room change in productivity. The recent increase in abilities of LLMs to generate text is starting to feel similar.
What is still hard
What now controls the productivity curve for programmatic descriptions of geology at point X are several related constraints.
First, can you figure out if the result is reliable enough to use? A prompt can work fine two or ten times before giving an unexpected result on the eleventh. To some extent both prompts and deterministic functions can be used to validate responses. The number of geology terms in a Wikipedia page can help provide a clue to whether that page is a valid result to summarize for the regional geology. However, the wikipedia page for "geology" has a lot of geology terms even though it is not at all what's wanted for the geology of the region around Oslo, Norway. Prompts combined with traditional natural language processing is probably more effective, but creating effective methods requires creativity, and at least initially, a well-informed human looking at the results.
Second, are there enough data APIs and sources of unstructured factual information with the right information for your task? Some states are too small to have a wikipedia page titled "Geology of [insert state]". Other times the state or country boundaries are much less useful than other boundary terminology. Related to this data limit, is the question of having validation and fallback methods. The impact of a "wrong" or "missing" piece of information is going to affect how much time is spent on the problem.
Third, the factual data APIs are not always accurate. Macrostrat is far and away the easiest to use and most accurate geology data source I have found that works at some level pretty much everywhere. That being said, it has told me information that I know to be wrong. I can remember driving through Kentucky looking at sandstone along the road cuts while Macrostrat told me the area was 100% limestone. The problem of data accuracy limitations are even more pronounced once you're outside a country that has both detailed geologic maps and advanced open data policies.
Fourth, what is accurate or useful is at times subjective. I often would like to skip the very recent unlithified "dirt" at the surface and just be told about the bedrock geology it hides even if I can't see it. However, someone specializing in geomorphology might want to know about that "dirt". At the other end of the spectrum, I can remember walking on a beach in Panama where a small bit of pillow basalt was exposed on the beach about the size of a large car. Everything else on the island I could see was much younger sandstone. The Macrostrat API would have likely told me that the entire island was sandstone and skipped the tiny bit of basalt peaking through even though to me that was far and away the most interesting part from a geologic story perspective as it spoke to oceanic crust being pulled apart at a mid-oceanic ridge. You could build in options to allow the user to choose what they want to hear about using traditional programming, but the number of options and the complexity of the user interface needed to make that work is a problem. To some extent, large language models make this problem easier to solve as the user can influence what information is provided themselves with a prompt, but it is still a hard to solve problem when the user & developer are different people.
Fifth, and most importantly, can you build something that fits into the workflow of the user? This experiment was basically just producing a string of text for myself to consume as part of the experiment. I can't imagine many people would want just this. How would you package this type of thing into a useful application for specific users trying to do specific tasks in a specific situation? To create narratives for a "roadside geology" or "train-side geology" experience is different from a user interested in only one specific point. Users with a geology degree might want to know different information than a second grader. As mentioned previously, understanding variable needs and providing appropriate information presented in appropriate ways for different types of users is a harder problem than what was accomplished in this experiment.
Conclusion
Also as a reminder, I do not speak for my employer here. This is a weekend side project for myself to learn.
Scratching the surface of possibilities but feel more productive using LLMs are one tool of many
I still feel like I have no idea what I am doing. Solving problems with LLMs opens up new approaches that I am still wrapping my head around. However, this project gave me some insights into why LLMs are so promising across a range of different possible applications. This is just a little side project created after several hours of work on a weekend plus a few hours while watching TV. Yet, I got quite a ways towards the end goal.
Hoping others will try to build on this experiment
I am excited to see what happens next in this space, and I'm writing this blog post in hope that others might try to build on this approach a little more. All the code is available in the LAGDAL repository & open source licensed. LAGDAL is an acronym that stands for 'LLM Assisted Geology Descriptions of Arbitrary Locations'.
Where to find more information
If you want to learn more about LLMs, you can check out official resources from OpenAI, Azure OpenAI, LangChain, or Semantic Kernal. You could also scroll the twitter search results for #GPT3, #ChatGPT, #OpenAI, #LLM, etc.
If you want a more curated set of observations and demos to learn from written from a single perspective, I recommend checking out Simon Willison's blog. He creates useful side projects to explore the capabilities of new technologies and then writes about them effectively and more often than I check my mail.