- Published on
Opportunities to leverage code repository and package metadata for new open source experiences
Reading does not scale but experiences built upon standardized metadata do
Reading is a great way to learn about a code repository or an open source package that you use as a dependency to a code project, but it doesn't scale to hundreds or thousands of code repositories or packages. This fact opens up opportunities to leverage metadata from code repositories and package managers to create experiences that help users do things as if we had read thousands of code repositories or packages.
To help explain, here are a few examples of what people could do differently if they could easily read and remember details of hundreds or thousands of code repositories or packages
If people working in OSPOs (Open Source Programs Office) could read and remember details about the hundreds or thousands of code repositories their company releases on GitHub, they could give best practice guidance or create compliance requirements that are fit-for-purpose instead of one size fits all.
If developers deciding which open source package to use as a dependency could read and remember details of all the different
options, they could make safer decisions on which package to use and perhaps use the most sustainable option with a healthy
community rather than the first one they find or whatever one is used in a three year old demo.
If people in charge of a product built from thousands of dependencies could read and remember details about the community building each of the thousands of dependencies, they would know which few dependencies have been abandoned by their maintainers and should be replaced or which of those thousands of dependencies should be invested in to ensure their long term health and by extension the health of the product.
Of course, it is not possible for people to read and remember details about hundreds or thousands of code repositories or packages. That is where experiences built upon large amounts of easily accessed and standardized metadata come in.
Examples of recent work at Microsoft
I have been fortunate to work on a few different projects inside Microsoft that leverage metadata from code repositories and package managers to create new experience for Microsoft's developers. An overview of some of this work was recently published in a blog post titled "Microsoft Open Source Programs Office—Tuning the answers to Open Source questions" on the Microsoft Open Source Blog. The blog post details multiple different OSPO projects, but I'll highlight the few here that I worked on in the past year.
Directly copied from the blog post:
Question:
How do we help developers make good choices about the components they are choosing beyond a minimum bar of compliance? How can that tool help us understand sustainability risks and contribution needs once we take on that dependency?
Answer:
Component Information Dashboard: Using community health insights from Community Health Analytics in Open Source Software (CHAOSS), public information on packages from ClearlyDefined.io, OSSF, and Ecosyste.ms, we’ve built (and continue to improve) a prototype experience that surfaces attributes of heightened risk for sustainability. Come to our panel discussion on the topic: OSS Viability and Project Selection.
Question:
With the xz backdoor human exploit a primary topic at the Open Source Summit, what metrics can we share and collaborate on with others?
Answer:
One thing might be, some experimentation we’re doing with a metric called the ‘Nebraska Factor’ (after the well-known XKCD dependency cartoon); and discussing where human observations fit. Find us at the summit or CHAOSS OSPO working group to chat more on this topic.
Question:
How can we help Microsoft developers describe the impact of their upstream open source contributions beyond their own needs/impact?
Answer:
Rewards season personalized maintainer emails: Often, an upstream contribution helps other teams at Microsoft. We’ve created personalized ‘maintainer emails’ to show exactly how many other projects benefited from a contribution. Sometimes it’s in the hundreds! This directly demonstrates ‘contributions to the success of others’, which is an aspirational area of impact for all Microsoft employees.
Question:
How can we help Microsoft developers/teams of open source packages learn more about their internal impact?
Answer:
Component Intelligence: A suite of pre-built Kusto queries and dashboards that Microsoft developers can request access to that maps out internal usage of packages by repository, service, organization, etc. This helps them see real examples of their code being used, tell stories about usage in key products, locate potential candidates for user interviews, and track changes in usage rates by version and package over time.
Question:
What might be the primary characteristics for groupings of repositories? How can we provide different compliance experiences based on those characteristics?
Answer:
Repository cohorts: creating standardized types of repositories via metadata helps us be more strategic in our many efforts to raise the bar for compliance and more. Check out this demo or code in the OSPO GitHub repository. Also check out Justin’s talk on this topic!
Repository Cohorts
Repository Cohorts deserves a special note as it is the only one of these that has related code that's been open sourced.
As described in the slides from the 2024 Open Source Summit North America talk, code to calculate repository cohorts from repository cohorts is available in the microsoft/ospo repository's repository_cohorts directory. You can see a demo of repository cohorts applied to 10,000+ public Microsoft repositories or try it out on your own GitHub organization in an Observable demo.
Repository cohorts are an answer to the imaginary scenario mentioned above that asks what OSPOs would do differently if they could read and remember the contents and purpose of thousands of code repositories their organization has released.
Nadia Cohorts
For anyone who has read Nadia Asparouhova's book "Working in Public: The Making and Maintenance of Open Source Software" repository cohorts will be interesting as it is a way to programmatically categorize all of an organization's repositories by the community types of federation, stadium, club, and toy that were presented in the book as a conceptual model.
The image below shows counts of repositories in the Azure GitHub organization that are categorized into the four Nadia community types, plus a fifth, "mid", for repositories that are not strongly in either of the four and somewhere in the middle.
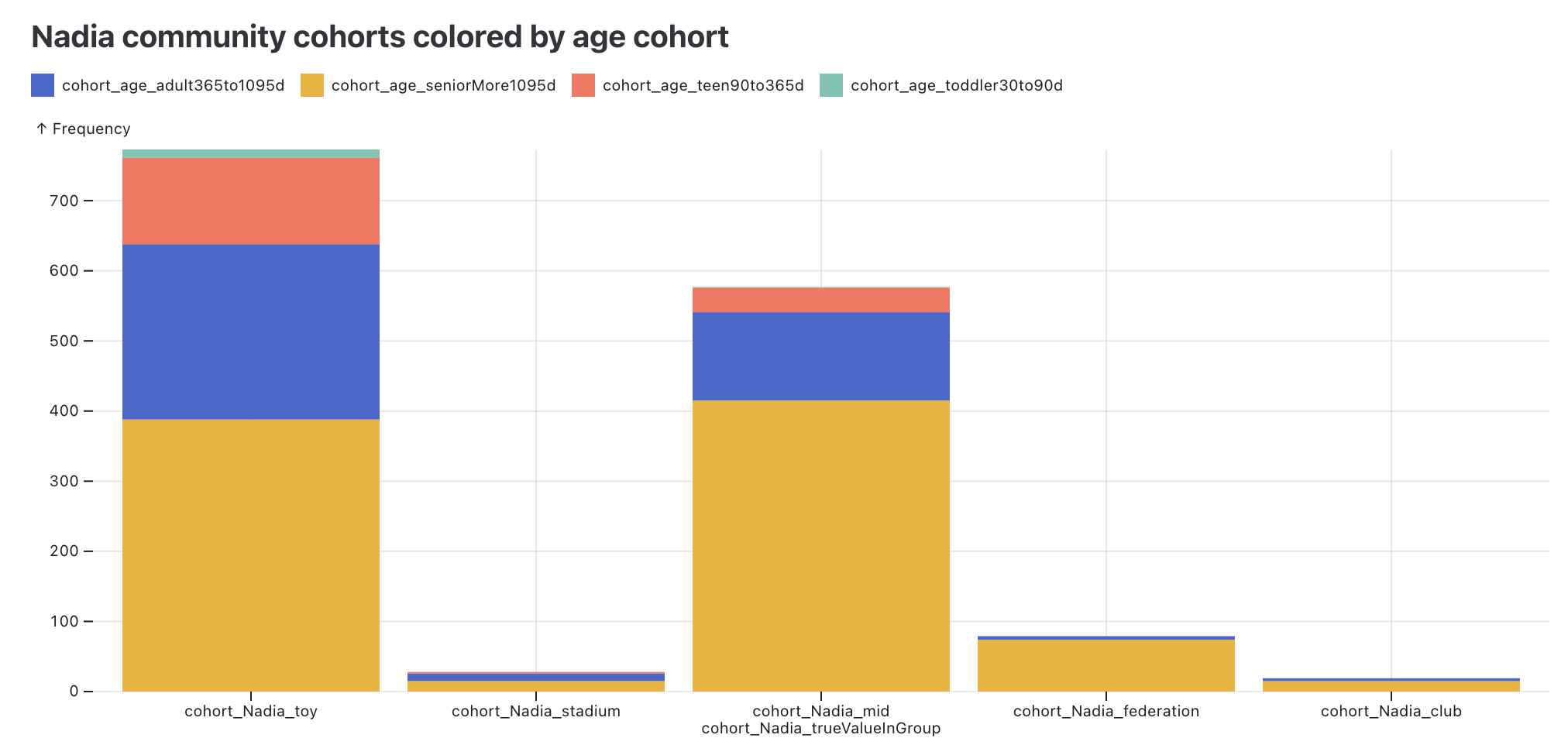
These counts are based on metadata thresholds chosen that seem to make sense but if you think different thresholds make more sense, feel free to submit a pull request to the microsoft/ospo repository's repository_cohorts directory.